這邊(點這)有個人覺得不錯的Keras簡介,可以參考看看。
好啦!!話不多說啦!!學程式還是要親自動手才算數,就來試試看Keras囉!!這邊要做的是基礎的手寫數字辨識MNIST。
首先先把需要的module先輸入:

其中numpy跟pandas都是常用的module,而keras.utils則是keras的工具庫。
接下來下載MNIST資料庫:

接下來先看看利用matplotlib第一筆資料到底長得怎樣:


結果第一個果然是5。
接下來進行數據的前處理,首先把28x28矩陣以.reshape方法轉換成一維的向量,之後計算會比較方便,後面接著.astype則轉換成float32的資料型態:


從結果看出來是沒有問題的(因資料太大,上圖只有一部分資料)。
不過最後還需做一個動作,把資料歸一化,避免資料運算數字過大,有助於提升準確率,因資料是從0~255(256個灰階),所以我們把資料全部除255,並顯示出來看看:

接下來就是label(標籤)的資料處理了,這部分比較複雜點,因統計的數據(data)分成兩大類:numerical和categorical,numerical有數量單位,而categorical則沒有數量單位,例如身高體重有單位(cm、kg),但血型只有數種,所以是categorical,簡單來說就是只有類別(category)。而MNIST最後的結果就是要分成十個不同的數字,換句話說我們想做的是分類,因此這邊使用了所謂的"One-Hot Encoding"的方式把10個數字轉換成有binary特徵的數值,所以這邊利用np.utils.to.categorical的指令將label轉成one hot encoding的型態:

接下來是模型的建立,這邊就是Keras的強項,來看看怎麼做:

其中Sequential表示之後使用model.add的方式將神經元一層一層的往上加就可了,第一層是輸入層與隱藏層,使用Dense(是Keras中全連結線神經網路,就是每個node之間都會連結),有256個神經單元(units),輸入資料dimension為784(輸入層必要值),起始核心為normal,換句話說就是使用常態化的亂數起始權重(Weight)及偏差(bias)值,輸出函數則為Softmax。接下來就再簡單疊一層輸出層就可。model.compile則建立訓練參數,loss使用categorical_crossentropy的方式,optimizer則用adam的優化方法,一般分類問題則設定使用accuracy準確率評估模型。
最後使用model.fit的指令啟動訓練啦,模型資料會存在train_history裡,validation_split指的是有20%的資料會用在驗證(validation)模型之用,epochs表示分10次訓練週期,batch_size則是設定一批次的訓練資料,verbose(中文有報告的意思)設定2則是把訓練報告顯示出來(設定0就是不輸出;設定1則顯示進度條),最後執行後每一個epoch的accuracy與loss值。到這邊總算是完成整個過程~~(累死了)。
還一個有用的指令是.summary,可以看一下我們建立模型的摘要:

總結一下整個程式如下:

不過只看數字可能對模型比較沒感覺,所以還是需要作圖看看。上述提過最後的模型結果都存在train_history之中,我們先看看train_history是啥:

裡面有不少方法可以使用,例如.history:


有了這些data就可以繪圖了:
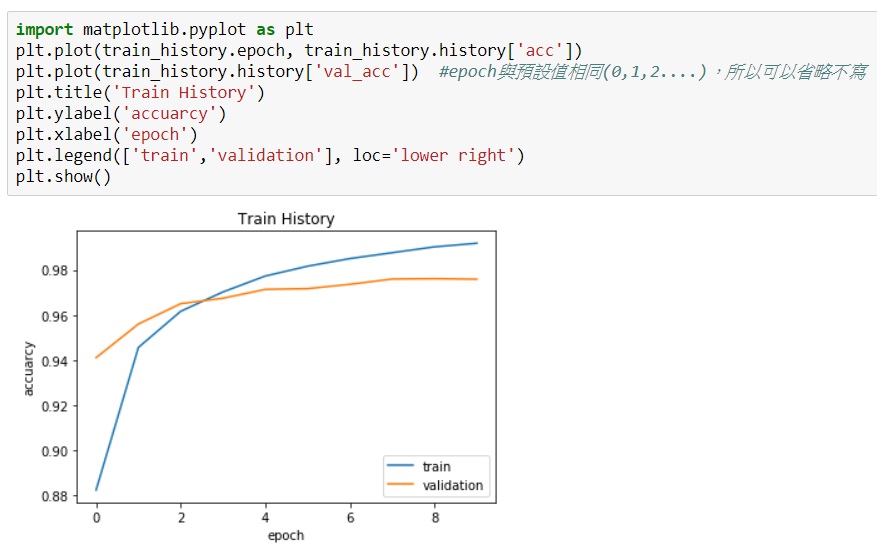

訓練完model之後,接著就是以Test的資料測試,這部份很簡單,使用model.evaluate指令:

看不懂結果?

這樣應該就清楚了,model.metrics_names很清楚告訴我們結果就是測試後的loss及accuracy,準確率達97.6%。
參考資料
TensorFlow+Keras深度學習人工智慧實務應用
沒有留言:
張貼留言