CNN一般來說比先前的基礎ANN多元感知器能達到更高的準確率,利用卷積層及池化層能提取圖片的特徵,增加辨識的能力,CNN的基礎理論從這裡可以看到不錯的介紹,所以就不囉嗦,直接來看看Keras程式吧。
先import需要的資料庫及CIRAF-10資料集,因Keras已內建,可以直接使用cifra10.load_data()的指令讀取:

另外開一個dictionary(label_dictionary)儲存每一個label數字代表的類別(共十種)。

可以知道有訓練圖形(image)資料50000筆,驗證(Test)資料則有10000筆,每一筆資料為32x32的矩陣,最後一個維度是RGB三原色三個數字,代表圖素的顏色。標籤(label)的資料則有一個數字表示圖片的類別。
我們可以看一筆資料中的一個畫素:


接下來進行數據的預處理,同樣包含了設定類型(float32)並標準化以提升準確率,可以看一下第一筆資料的第一個圖素,確定有沒有錯誤:

另外有一點要注意的是,跟ANN有差異的地方在於資料轉換,MNIST原本資料是(60000, 28, 28),ANN轉換成一維的784個數字(看這邊),而CNN必須保持圖片二維的特性,之後才可以利用卷積層及池化層提取圖片的特徵。
標籤方面也是必需轉換成one hot encoding的型態(也一樣可以參考前篇):


總結一下整個程式如下:

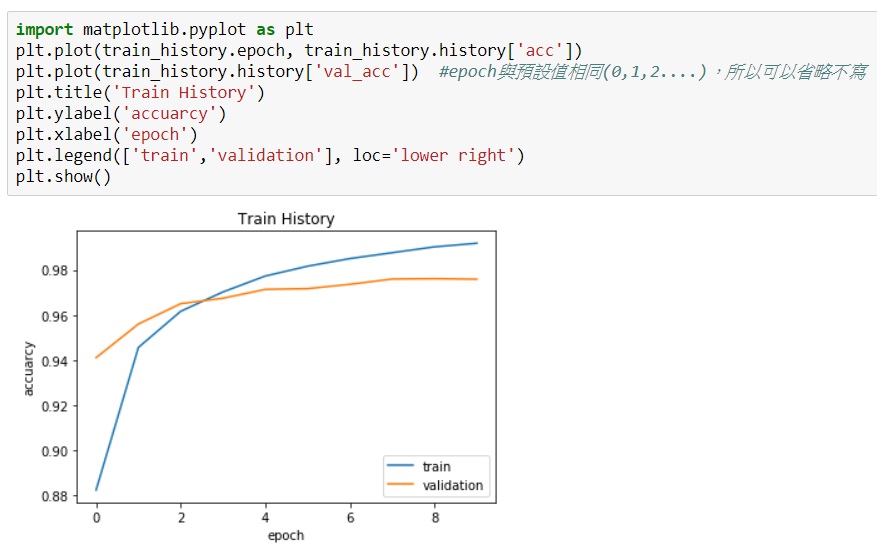
同樣地以圖表看看最後結果:


可以清楚看到大量使用Dropout(最後一次參數為0.5)確實可以降低overfitting的現象,train及validation的差異較小。
訓練完model之後,接著就是以Test的資料測試,同樣使用model.evaluate指令:

測試結果的loss為0.824而準確率(accuracy)約72.6%,相較於先前的MNIST資料集確實低很多,當然圖片為彩色且雜訊多應該是主要原因吧。
接下來就是進行預測囉,仍然利用model.predict_classes()的指令預測,


接下來仍然利用pandas的.crosstab指令產生confusion matrix(混淆矩陣),可以清楚哪些是正確預測的部分(對角線),哪些是預測錯誤的部分了。例如這次來看看標籤是0但預測成5的有8筆資料。

同樣地先建立下列標籤與預測值對照的完整表格,先看前三筆資料,跟先前的一樣,所以應該錯誤機率不大:

接下來看看哪些是標籤為0(飛機)但卻是預測為5(狗)的資料:


參考資料
TensorFlow+Keras深度學習人工智慧實務應用